Async rust has a few parts that doesn’t feel ‘rusty’ at all. Rust is pretty good at “forcing” local reasoning but async cancellation (drop of Future etc.) leads to non-local reasoning which leads to hard to follow sequence of events that leads to subtle bugs. I recently learnt about futurelock from this excellent blog post.
The RFD (Request For Discussion) from Oxide that describe futurelock (https://rfd.shared.oxide.computer/rfd/0609) is easy to read by an intermediate Rust programmer. Reading this RFD made me a little bit nervous about async which I though I knew decently well.
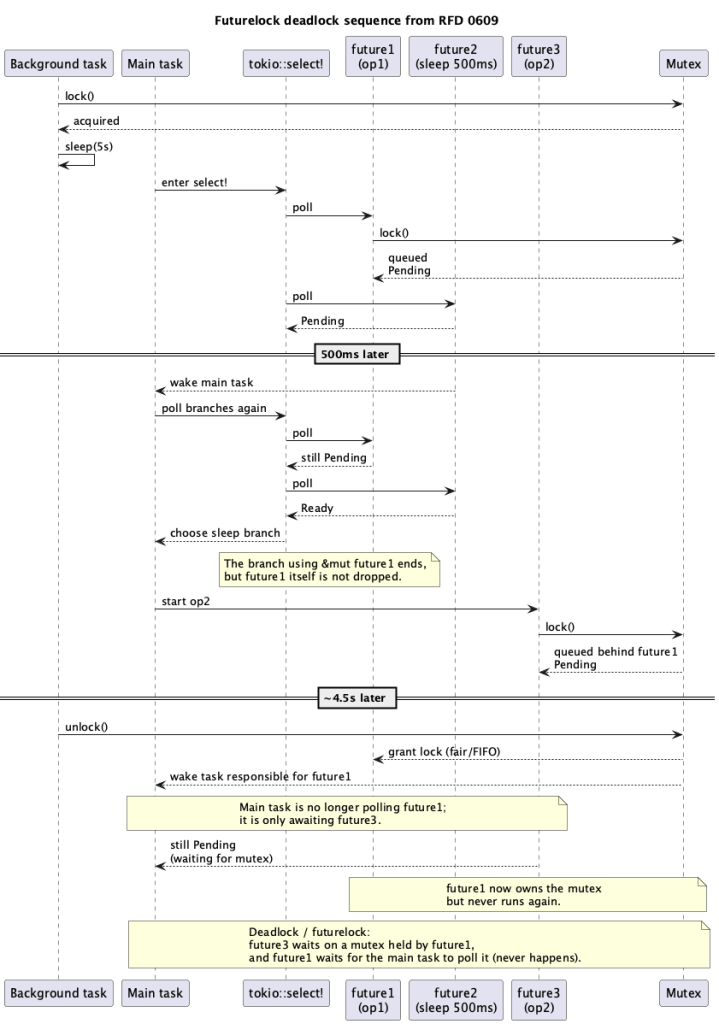
I created this diagram that summarizes the sequence of events in the RFD that eventually leads to the deadlock/futurelock. You can refer to this diagram when re-reading the RFD. It helps a lot.
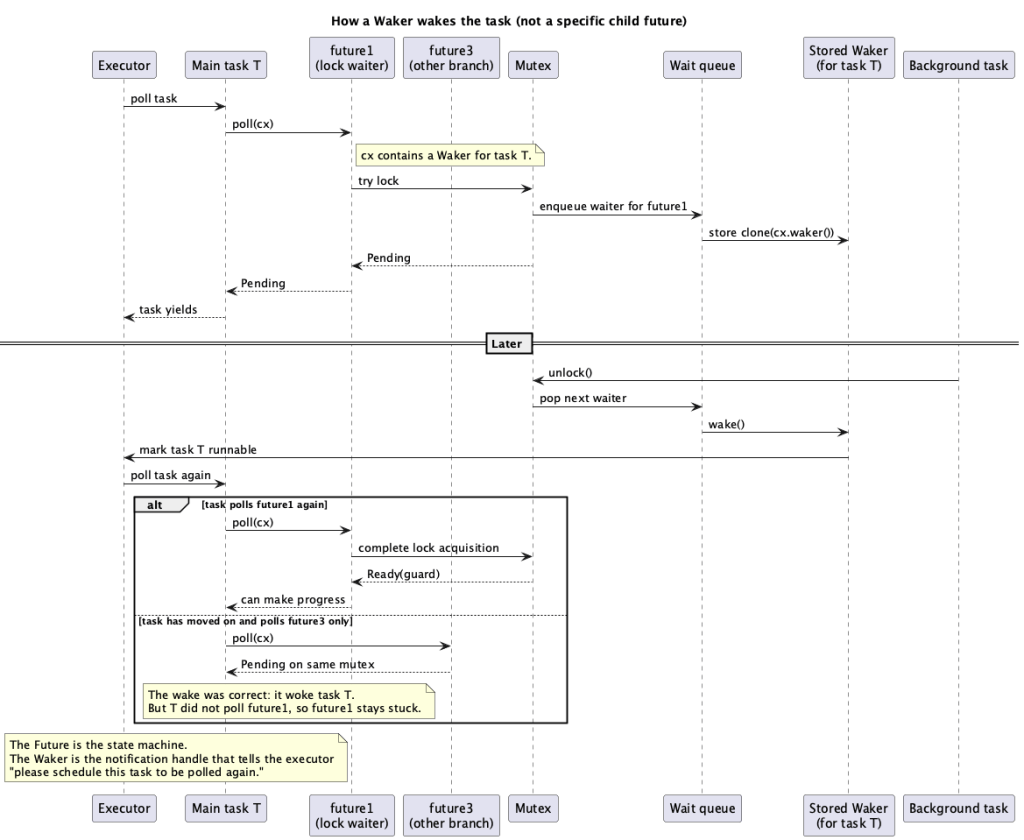
I also dug a little deeper into the mechanism of Mutex waking up the relevant tasks when it is unlocked. In the past, I’ve written state machines with callbacks and I think about async in state-machine terms. Future and Waker works together to implment state-machine with callback.
Here is another diagram which shows how Waker is used to implement callback like mechanism for the example in the RFD.
I am going to do something terrible — store videos in a SQL database!
I have some requirements that makes it an acceptable plan. I am building a “stream store” S. Once videos are stored in S, users should be able to fetch a video segment (in color or grayscale) between two given timestamps at a given FPS. One should also be able to annotate frame later e.g., “this frame has a face in it”. I’ll read the incoming video stream and save data as frames to a database (in addition to storing raw videos on a backup server).
The primary job of S is to provide frames for CV analysis, so serving pixel-perfect video stream is not a requirement.
The stored frames should be “good enough” can our CV algorithms/pipeline works without a performance drop.
The cost of storing frames should be as low as possible as long as the above requirement is met.
I am going to extract frames from video as JPEG — a lossy compression format. But what should be the quality of JPEG?
Experiments
I downloaded a sample mkv file — 1080p at 30 FPS to do simple analysis.
I wrote a script that extract frames from the mkv using ffmpeg. The argument -qscale:v set the quality of frames: 2 is the best and 32 is the worst.
ffmpeg -i ../sample_1280x720.mkv '%04d.png' generates PNG folder which is 1.3 GB, almost 78x of original size. PNG is a lossless format. This is as bad as its get.
ffmpeg -i ../sample_1280x720.mkv '%04d.jpg' generates JPEG with default quality picked by ffmpeg. It generates 33 MB of data. Almost 1.94x more. Great!
ffmpeg -i ../sample_1280x720.mkv -qscale:v 2 '%04d.jpg' generates JPEG with best possible quality. The generated size is 188 MB (almost 11x more!).
I did the same on a different file recorded at 60fps (original size . The data is below.
A video recorded at 60FPS takes more than twice the size compared to fps=30 case. Note video are using codec H264 (MPEG-4 AVC (part 10) (avc1)) which AFAIK compresses pretty well if two consecutive frames don’t differ too much. So this is expected.
Our recordings have the same feature. The interesting events happens rarely. We might drop many frames from the database after doing a quick analysis to figure out if they contain something interesting or not. So in the end, we don’t even have to store so many frame.
I think qscale:v=20 is a good default for my use case. Also I don’t have to extract frames at the same rate as they are recording. I am interested in events at the timescale of ~100ms and anything faster than 20FPS is overkill. i can just extract at 30 fps.
ffmpeg has a handy cli option -filter:v "fps=30" to fix the extraction fps to 30. Here is bonus rust code that does this. Don’t copy-paste blindly, it may not work.
/// Explode the given video into JPEG frames.
///
/// - *path*: Path of video file
/// - *fps*: Extract these many frames per seconds. The video may contain
/// more or less frames in a second.
pub fn extract_jpegs<P: AsRef<Path> + std::fmt::Debug>(
path: P,
fps: u16,
recording_start_timestamp_ms: i64
) -> anyhow::Result<usize> {
anyhow::ensure!(path.as_ref().exists(), "{:?} does not exists", path);
tracing::debug!(
"Extracting frames from {:?} for fps={fps} and jpg qscale {:?}.",
path.as_ref(),
self.qscale
);
let inst = Instant::now();
let mut cmd = std::process::Command::new(&self.ffmpeg_bin_path);
cmd.arg("-i").arg(path.as_ref());
// Extract at a given fps. Thanks <https://askubuntu.com/a/1019417/39035>.
cmd.arg("-filter:v").arg(format!("fps={fps}"));
if let Some(qscale) = self.qscale {
tracing::debug!("Setting qscale to {qscale}");
cmd.arg("-quality:v");
cmd.arg(qscale.to_string());
}
cmd.arg(self.frame_directory.join("%05d.jpg"));
let output = cmd.output()?;
anyhow::ensure!(
output.status.success(),
"Command failed\n.{}\n{}",
String::from_utf8_lossy(&output.stdout),
String::from_utf8_lossy(&output.stderr)
);
tracing::debug!(
"Extraction to {:?} is complete, took {:?}.",
&self.frame_directory,
inst.elapsed()
);
}
For the last couple of weeks, Ookie has been going to a day-care for a few hours. She gets to play with other kids there. “Playing with other kids” has been the reason for sending her there. After a few days of fuss, she now seems to be enjoying her time there. My very friendly neighbors think that she is too young to go to day-care!
Somehow I managed to run 400 km so far! My pace has been slowest. I still need to complete 600 km in the second half of the year.
I’ve started paying for RUNALYZE. It is nice that more and more services are offering purchase-parity plan for subscription for Indian users. I’ve been using jonasoreland/runnerup: A open source run tracker for a long time to sync my runs with Runalyze/Strava. One dollar=Rs 100, but it is roughly Rs 30 in purchase parity, so you have to reduce the pricing by third for Indian users! If you are doing this, I’d be happy to work for you for a purchase parity adjusted salary😛.
I had a minor meltdown at work 😭. Not proud of it. It’s hard to keep cool when many co-workers write almost empty email without a subject/body to report bugs. I’ve been trying to get them to use GitLab issues for a few months now. Either, I need to disengage from work a little at this workplace, or find a place where co-workers are adults and not only they come to work but also know how to structure and plan it.
I read Programming as theory building : Naur.pdf and found it illuminating. I am pretty sure I’d have yawned reading it some 10 years ago. This article — written a year before I was born — put “programmers” at the center of software development. I don’t think I can reduce this article to soundbites. Do read. I learnt about this article from HN.
– I wrote another small utility to remind me that a LWN article has finally become open. I am not able to pay for LWN subscription due to HDFC Bank related issues and I forget to revisit the link when it is open. Perhaps I can rent a VPS in this money and read the article two weeks later?! LWN is a great resource and I feel bad for not paying for it though!
– My Wallet from Budgetbakers is no longer syncing with HDFC Bank. Their support is working on the issue. HDFC seem to have changed their login flow again! My another bank, DBS Bank, doesn’t have saving account API🤣. I opened account here thinking that they are “tech-savvy”!
– I’ve been thinking about hiring a lot these days. At my current company which is an early stage startup, they have been struggling to hire a dev for the last 5 months! I was part of a few interviews — some went well and most were meh, but not able to hire for 5 months feels a bit extreme!
– Both mango trees in my street has mangoes this year! Here is my daughter Ookie playing with her friend. Fortunately, like many streets in Bengaluru, this street is a dead end and have no traffic.
I took a few interviews this week. One candidate was amazing and one was pretty good. A rare week with two good interviews! Interviewing is hard and I am becoming more and more sympathetic towards interviewers.
I grew up in North India. Compared to candidates from there, South Indian candidates almost never lie during interviews — with or without a straight face. I also find them to be better co-workers. There have been a few notable exceptions on both sides though.
I got a new color printer with ink tank this time. It is from Brother, which has pretty good Linux support. I downloaded script from their support page, ran it and it set up the printer without any fuss. Previous one was a HP with cartridges and refilling them was always a pain. Also, hplip is not always up to date. It is nice to take a printout of an important document such as resume and read with attention they deserve. Many candidates spent days on them!
I was looking for a general database migration tool for PHP. Found Phinx and quite like it. Codeigniter inbuilt database migration wasn’t usable because I moved my project from FastAPI and earlier migration were handled by https://github.com/sqlalchemy/alembic. If you don’t setup your database with CI4, it’s not easy to use it for migrations!
No matter how well you plan your database, there will always be need for migration since business requirements keeps changing. Alembic is great if you are in Python world!
I totally understand if someone get the temptation of using No-SQL in the beginning of a project and later continued with it!
I finished a few courses at Coursera. Most of them are related to “soft skills”. You don’t have to spend hours doing assignments in these courses.
With that little time investment, I got a lot of insightful tips and knowledge. Do not discount “easy courses”. Many things sound easy once there are told and this fact should not reduce their value. I wouldn’t even think of these titbits and tips otherwise.
We went out for dinner last night. It was for Anzal’s farewell (at https://maps.app.goo.gl/uun78ux8QCDEnKKS9.). A dog friendly place, they have food for them on the menu. But Kaalu was spooked by a giant rat in bushes and spend most of her time on high-alert. She definitely did not enjoy it. Ookie, on the other hand, had a good time.
Rust web frameworks have subpar error reporting | Luca Palmieri is a nice article. Rust has the most amazing error handling, and manually translating them to HTTP responses doesn’t feel “rusty” enough. It’s nice that people are actively solving DX problems.
I am active on LinkedIn again. I deleted my LinkedIn profile twice, more recently last January. Perhaps third time a charm?!
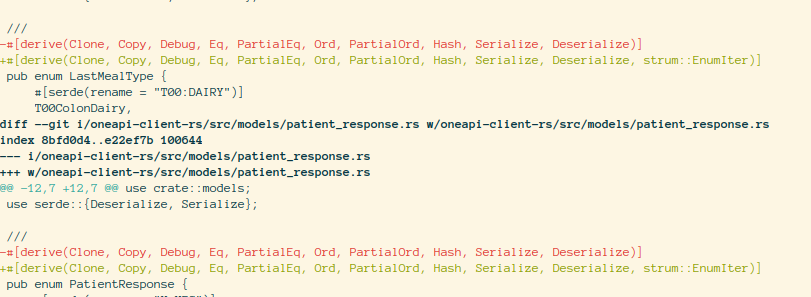
I needed to add more derive traits on the enum generated by openapi-generate-cli e.g. strum::EnumIter.
First, dump the templates using the following command openapi-generator-cli author template -g rust . This will write templates to the directory out.
Now edit the templates inside out directory. I had to add strum to Cargo.mutache and strum::EnumIter inside derive of all pub enum inside model.mustache file.
Now regenerate the client using openapi-generator-cli generate -t out -i openapi.json -g rust -o api-client-rs
And you have updated client.
Here are some diffs
PS: I could not get the local version to run on my system. I used the following docker command
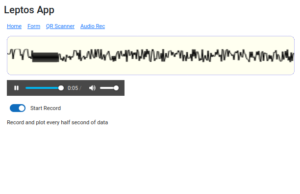
There is also a QR scanner that may or may not work in your browser. I used a third party crate that I patched to compile with Leptos 0.7 but did not test is thoroughly.
leptos-use (https://leptos-use.rs/) makes it easy to access browser’s API such a audio/video streams. The audio recorder records the audio in chunk of a few seconds and plot the raw values on the canvas. The plotting is very basic here!
I tried using https://thawui.vercel.app/ components but could not make it work with my slightly complicated hooks that update the local storage. I reverted back to standard leptos input component.
## [component]
pub fn Form() -> impl IntoView {
let storage_key = RwSignal::new("".to_string());
let (state, set_state, _) = use_local_storage::<KeyVal, JsonSerdeCodec>(storage_key);
let upload_patient_consent_form = move |file_list: FileList| {
let len = file_list.length();
for i in 0..len {
if let Some(file) = file_list.get(i) {
tracing::info!("File to upload: {}", file.name());
}
}
};
view! {
<h5>"Form"</h5>
<Space vertical=true class=styles::ehr_list>
// Everything starts with this key
<ListItem label="Code".to_string()>
<input bind:value=storage_key />
</ListItem>
// Patient
<InputWithLabel key="phone".to_string() state set_state></InputWithLabel>
<InputWithLabel key="name".to_string() state set_state></InputWithLabel>
<SelectWithLabel
key="gender".to_string()
options=Gender::iter().map(|x| x.to_string()).collect()
state
set_state
></SelectWithLabel>
<InputWithLabel key="extra".to_string() state set_state></InputWithLabel>
</Space>
}
}
## [derive(Debug, strum::EnumIter, strum::Display)]
enum Gender {
Male,
Female,
Other,
}
## [component]
pub fn InputWithLabel(
key: String,
state: Signal<KeyVal>,
set_state: WriteSignal<KeyVal>
) -> impl IntoView {
let label = key.split("_").join(" ");
let key1 = key.to_string();
view! {
<Flex>
<Label>{label}</Label>
// Could not get thaw::Input to change when value in parent changes.
<input
prop:value=move || {
state.get().0.get(&key1).map(|x| x.to_string()).unwrap_or_default()
}
on:input=move |e| {
set_state
.update(|s| {
s.0.insert(key.to_string(), event_target_value(&e));
})
}
/>
</Flex>
}
}
// SelectWithLabel is not shown. See the linked repo for updated code.
To make this problem concrete, I’ve downloaded database of all CVEs from https://github.com/CVEProject/cvelistV5 using git clone. I want to create API that can query this repository. I can think of the following available options.
Somehow ingest JSONs into a relational database and use SQL either using a third party tool or using a custom solution.
I’d have preferred 1 or 2 if I was writing a cli application. Since I am building a RESTful API, I’d prefer 3 since queries will be easier to write and integrate into other applications. Custom solution is also not a bad idea if existing tooling is not good enough or there are other constraints. Most databases like PostgreSQL and sqlite3 allows JSON to be inserted and queried.
For this exercise, I am not interested in performance. I can use caching to improve performance drastically later is need arise. I am looking for a solution that has the best DX — and if I am lucky doesn’t easily allow stupid mistakes!
Installation
The installation was a breeze. Single binary! It can also be used as Rust/Python library and third party integration for PHP are also available 💯.
$ wget https://github.com/duckdb/duckdb/releases/download/v1.1.3/duckdb_cli-linux-amd64.zip
$ unzip duckdb_cli-linux-amd64.zip
Archive: duckdb_cli-linux-amd64.zip
inflating: duckdb
(PY311) [dilawar@rasmalai cve_database_git (master)]$ ./duckdb
v1.1.3 19864453f7
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D
Great, seems to work!
Querying JSON files
For a sanity check, I did a “loopback” — print what you read. Just to make sure that engine is parsing JSON files. I passed a glob that matches all JSON files. Loading all files together raised an error — mismatch in schema.
D SELECT * FROM 'cves/**/*.json';
Invalid Input Error: JSON transform error in file "cves/2001/1xxx/CVE-2001-1517.json", in record/value 1: Object {"affected":[{"product":"n/a","vendor":"n/a","vers... has unknown key "tags"
Try increasing 'sample_size', reducing 'maximum_depth', specifying 'columns', 'format' or 'records' manually, setting 'ignore_errors' to true, or setting 'union_by_name' to true when reading multiple files with a different structure.
D
Fair enough warning about inconsistent schema across files and it suggested what I should explore. I like tools that hints at what to do in case of error💯.
I am not sure which one is the best option here though: ignore_errors or perhaps union_by_name is a better idea🤔? I am going ahead with union_by_name. I had to tweak the query little bit: SELECT * FROM read_json('cves/2000/**/*.json', union_by_name = true);
Nice!
Note that we are not yet inserting these JSON record into to a SQL table but rather processing them on the fly. I say this because I don’t see the opened database test.duck.db size to increase at all!
To insert these JSON records into SQL table that can be queries later, we use the following
D CREATE TABLE cve AS SELECT * FROM read_json_auto('./cves/2003/*/*.json', union_by_name = true);
100% ▕████████████████████████████████████████████████████████████▏
D select COUNT(*) FROM cve;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 1553 │
└──────────────┘
I am ready to append to this table and write queries.
Using python module
I did the same exercise as before using duckdb python module.
import duckdb
git_repo = _cve_repo_dir()
logger.info(f"Syching duckdb from {git_repo}...")
json_files = list(git_repo.glob("cves/*/**/*.json"))
con = duckdb.connect("cve.duck.db")
\# create table if it doesn't exists using a JSON.
first_json = json_files[-1]
logger.info(f"> Creating table using {first_json}")
con.sql(
f"CREATE TABLE IF NOT EXISTS cves AS SELECT * FROM read_json('{str(first_json)}', union_by_name = True)"
)
s = con.sql("SELECT * FROM cves;")
print(s)
Great, once I have table initialized with schema, I can insert entries from other files: INSERT INTO cves SELECT * FROM read_json('{str(file)}'). One has to ensure that other files have same schema. If not, then we get error while inserting.
TypeMismatchException: Mismatch Type Error: Type STRUCT(cveId VARCHAR, assignerOrgId UUID, state VARCHAR, dateReserved VARCHAR, dateUpdated
VARCHAR, dateRejected VARCHAR, assignerShortName VARCHAR) does not match with STRUCT(cveId VARCHAR, assignerOrgId UUID, state VARCHAR,
assignerShortName VARCHAR, dateReserved VARCHAR, datePublished VARCHAR, dateUpdated VARCHAR). Cannot cast STRUCTs - element "dateRejected" in
source struct was not found in target struct
But I just couldn’t figure out how to the resolve the following error. Looks like updating an existing table to support the schema of a new file is not supported out of the box.
TypeMismatchException: Mismatch Type Error: Type STRUCT(defaultStatus VARCHAR, platforms VARCHAR[], product VARCHAR, vendor VARCHAR, versions
STRUCT(lessThan VARCHAR, status VARCHAR, "version" VARCHAR, versionType VARCHAR)[]) does not match with STRUCT(collectionURL VARCHAR,
defaultStatus VARCHAR, packageName VARCHAR, product VARCHAR, versions STRUCT(lessThanOrEqual VARCHAR, status VARCHAR, "version" VARCHAR,
versionType VARCHAR)[], vendor VARCHAR). Cannot cast STRUCTs of different size
The solution to this problem in this case was simple. Each sub-directory contains files with the same schema. I created a table for each sub-directory!
2.7GB worth of CVEs were stored in 456MB of database file.
[dilawar@khaja keeda-py (download_cve_database)]$ du -sh cve_json_db.git/cves/
2.7G cve_json_db.git/cves/
[dilawar@khaja keeda-py (download_cve_database)]$ ls -ltrh cve.duck.db
-rw-r--r-- 1 dilawar dilawar 456M Nov 30 20:56 cve.duck.db
[dilawar@khaja keeda-py (download_cve_database)]$
I have somethat that may look like the output of tree like command. I want it a plain list wihtout nesting for further processing. I want to convert the following on the left to the one on the right.
Line 12 converts HashMap to a vector of vector where inner most vector is join of key with individual values. flatten converts vector of vector to a vector (akin to concat).
For last 3 months, my Zoho Mail client lost an essential features: desktop notification when a calendar event is about to occur. It sends in-app notification but it is useless since I don’t pay attention to that. Calendar notifications are much more important since most of them are social contracts and one must not mixed them with mere notification. I missed many meetings or got late by a few minutes. A developer easily lose track of time when working!
I wrote to Zoho support and they told me that they are reimplementing it a brand new feature that will enable this again. Note to product manager — don’t break a working feature unless the implementation is ready. And they claimed they have enabled the desktop notification just for me. To this day, I am yet to see a desktop notification from Zoho Email client. I double, triple check the settings and after 10 years of experience with software development, I can’t figure is how to enable this settings, this tool is not for me!
Given calendar iCal url, it sends you desktop notification if an event is about to occur. At the time of this writing, “about to occur” means in 3 minutes. You can tweak this and perhaps send me a PR if you make it configurable from the cli.
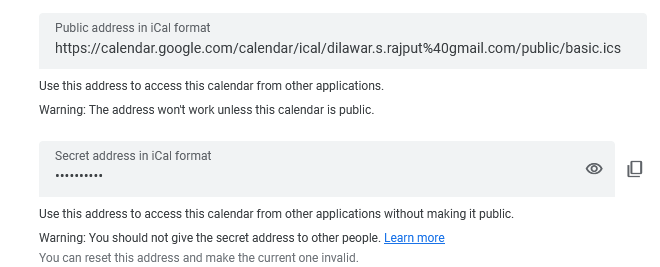
How to find an iCal url? Most calendar providers should have it enabled in settings. Here is a screenshot from google calendar.
You should use the private URL if you also want to see the title of the event.
/// Add to to PATH environment variable. If `append` is false, add to the
/// front of list.
pub fn add_to_path(path: &str, append: bool) -> anyhow::Result<()> {
use anyhow::Context;
use std::env;
use std::path::PathBuf;
let paths = env::var_os("PATH").context("empty PATH")?;
let mut paths = env::split_paths(&paths).collect::<Vec<_>>();
if append {
paths.push(PathBuf::from(path));
} else {
paths.insert(0, PathBuf::from(path));
}
let new_path = env::join_paths(paths)?;
env::set_var("PATH", new_path);
Ok(())
}